【論文紹介】High-Resolution Image Synthesis with Latent Diffusion Models
3.4K Views
October 25, 23
スライド概要
Web Developer / Research on generative models and continual learning
関連スライド





各ページのテキスト
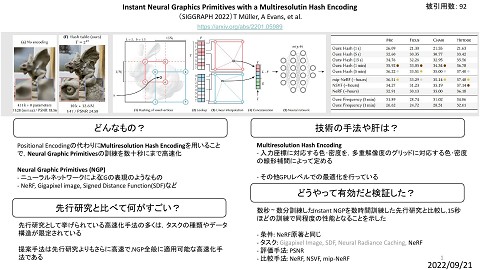
High-Resolution Image Synthesis with Latent Diffusion Models 被引用数: 387 (CVPR 2022)Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Bjorn Ommer https://arxiv.org/abs/2112.10752 どんなもの? ・ Diffusion Modelの訓練を高速化する手法 Latent Diffusion Model (LDM) ・ 事前に強力なオートエンコーダを学習させる ・ オートエンコーダの潜在空間で拡散モデルを学習させる ・ エンコーダで特徴マップのサイズを小さくすることで訓練を高速化 先行研究と比べて何がすごい? ・ 解像度の大きい画像に対しても,Diffusion Modelの訓練時間があまり大きく ならない ・ 条件付けのためのアーキテクチャが汎用的で,様々なタスクに容易に適用 可能 ・ Diffusion Modelをクロスアテンションで条件付けしているのも初 技術の手法や肝は? Two-Stage Image Synthesis ・First: 知覚的に重要な部分を大まかに表現 ・Second: オブジェクトのdetailまで表現 ・知覚的に重要でない部分に表現力を割かずに済む general-purpose conditioning mechanism ・ マルチモーダル学習が可能 ・ class-condition, text-to-image, layout-to-imageに使っている どうやって有効だと検証した? class-conditional image synthesisとinpaintingのタスクでSOTAを達成 ・ タスク: 画像生成(text-to-image, layout-to-image)/Super-resolution/Inpainting ・ データセット: CelebAHQ, FFHQ, LSUN-Churches, beds, ImageNet, (256x256) ・ 評価指標: FID, IS 1 ・ 比較手法: DDPM, ADM, BigGAN-deep/SR3/LaMa など 2023/02/01
どんなもの? Two-Stage Image Synthesis - 尤度ベースのモデルの学習は大きく2段階に分け られる First Stage (AutoEncoderの部分) - 知覚的に重要な部分を大まかに表現 Second Stage (Latent Diffusion Modelの部分) - より細かな特徴を表現する 2
どんなもの? Latent Diffusion Model 3
どんなもの? Conditioning Mechanism 4
どうやって有効だと検証した? サンプリング 5
どうやって有効だと検証した? どのくらいの学習時間 ? - ADMに比べて訓練を4倍高速化 - パラメータ数も半分 - ADMはV100一枚で116日 - 提案手法は29日 ? 6
どうやって有効だと検証した? text-to-image 7
どうやって有効だと検証した? Image super-resolution 8
どうやって有効だと検証した? Inpainting 9
どうやって有効だと検証した? Layout to Image semantic synthesis 10